浅析 Textmate 语法高亮规则运行机制
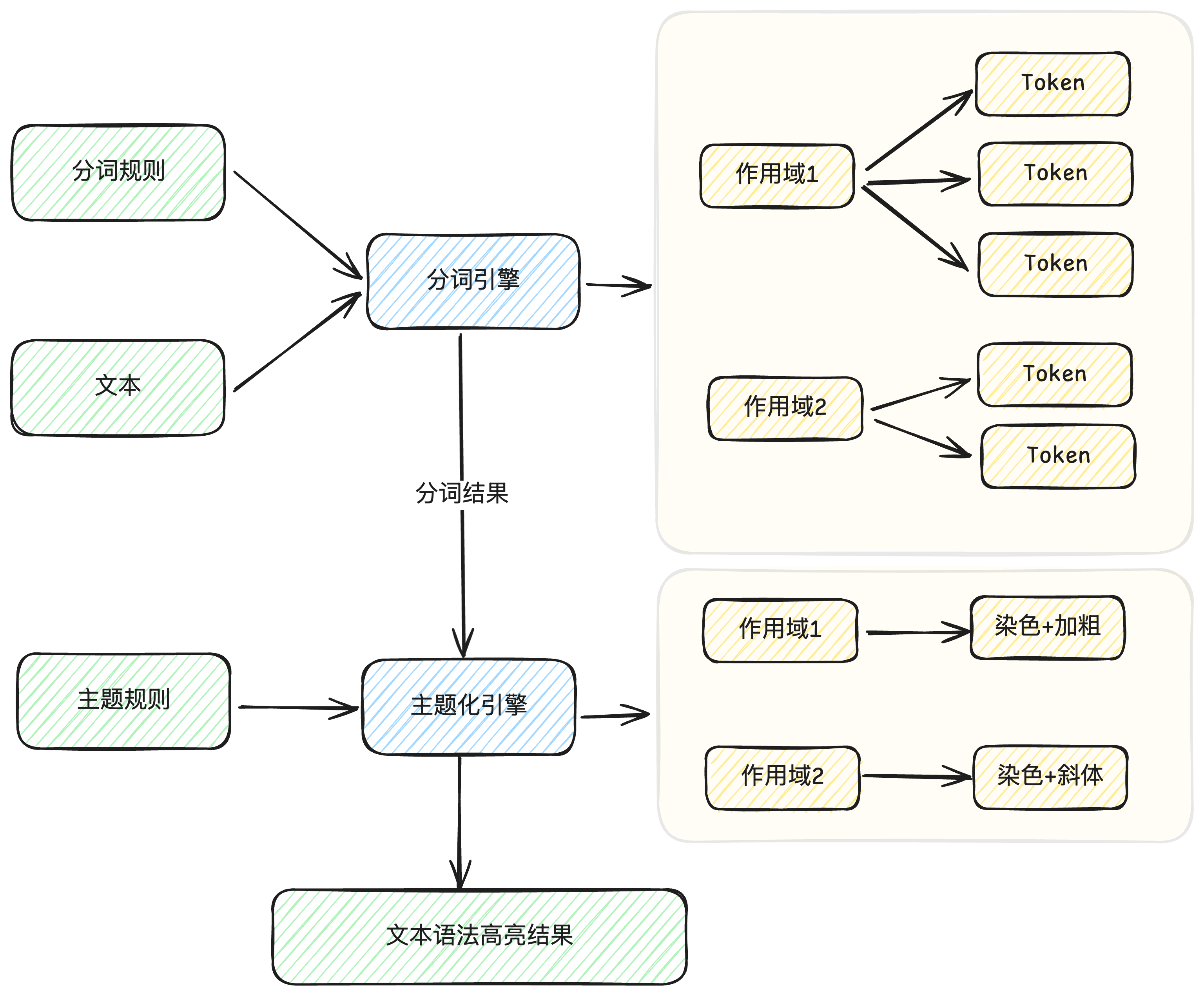
语法高亮是指在IDE或编辑器中,对文本进行**分词**,即将文本拆解为 Token(标记),每个 Token 都有对应的名称(作用域)进行标记。再配合主题样式规则,对不同名称的 Token 的进行**主题化**,以提高代码的可读性。
程序员离不开语法高亮,就像作家离不开标点符号一样。(你可以代入一下使用 txt 文本编辑器写代码的场景)
语法高亮由两个部分组成:
- 分词(Tokenization):将文本拆解为一系列 Token。
- 主题化(Theming):对 Token 进行样式渲染,如字体颜色、背景色、加粗等。
我们以 JSON 的语法为例,简单介绍一下语法高亮的过程。
首先分词引擎会对 JSON 文本进行分词,下图是将 JSON 文本进行分词后的结果,其中每个矩形所包括的文本都是一个 Token,每个 Token 都有一个作用域名称,例如 null 对应的是 constant.language.json 作用域。
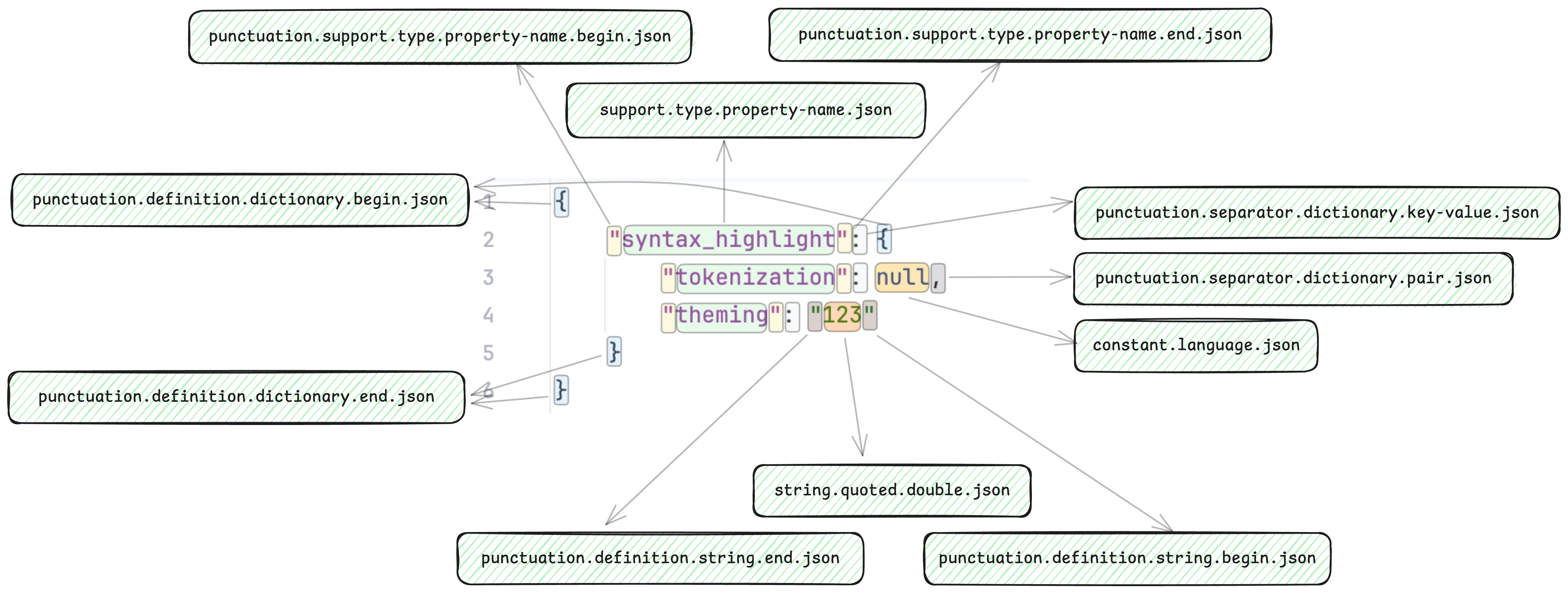
然后主题化引擎会根据 Token 的作用域名称,对 Token 进行样式渲染,例如将 constant.language.json 作用域映射为蓝色不加粗字体。那么 null 就会被渲染为蓝色不加粗字体。
2. 分词的实现方式
目前主流的分词实现方式大致有有以下三种:
- 基于**正则表达式**的分词:Textmate
- 基于**词法分析**的分词:Highlight.js
- 基于**语法树**的分词:Tree-sitter
- (如果有其他,欢迎补充)
本文只讨论 Textmate 的语法高亮规则编写。
Textmate 原是 MacOS 下的一款文本编辑器,其语法高亮规则是基于正则表达式的,但由于其规则简单易懂,且支持多种语言,因此被广泛应用于各种编辑器和IDE中,如 VSCode、Sublime Text 等。JetBrains 的 IDE 也集成了 Textmate Bundle 插件,可以直接导入 Textmate 的语法高亮规则。

3. 语法高亮规则的编写
VSCode 官方有一套关于编写 Textmate 语法高亮规则的文档,包含分词和主题化,详见:Syntax Highlight Guide。
本文不会介绍如何编写 Textmate 分词规则,只会浅析其工作原理。
4. Textmate 的分词规则运行机制
Textmate 的语法高亮规则是基于正则表达式的,Textmate 的语法高亮引擎会根据我们定义好的语法高亮规则对文本进行分词。分词的过程是从文本的开头开始,逐个字符地匹配规则,直到匹配到一个规则为止,然后将匹配到的字符标记为某种语法类型,然后继续匹配下一个字符,直到匹配到文本的末尾。
以下面的语法高亮规则为例:
{
"patterns": [
{
"match": "\\bhello\\b",
"name": "keyword.hello.jtgo"
},
{
"match": "\\w+",
"name": "string.word.jtgo"
},
{
"begin": "{{",
"beginCaptures": {
"0": {
"name": "expression.begin.jtgo"
}
},
"end": "}}",
"endCaptures": {
"0": {
"name": "expression.end.jtgo"
}
},
"name": "expression.jtgo",
"patterns": [
{
"match": "\\b(len|panic|print|println|min|max)\\b(?=\\()",
"name": "keyword.builtin-function.name.jtgo"
}
]
}
]
}
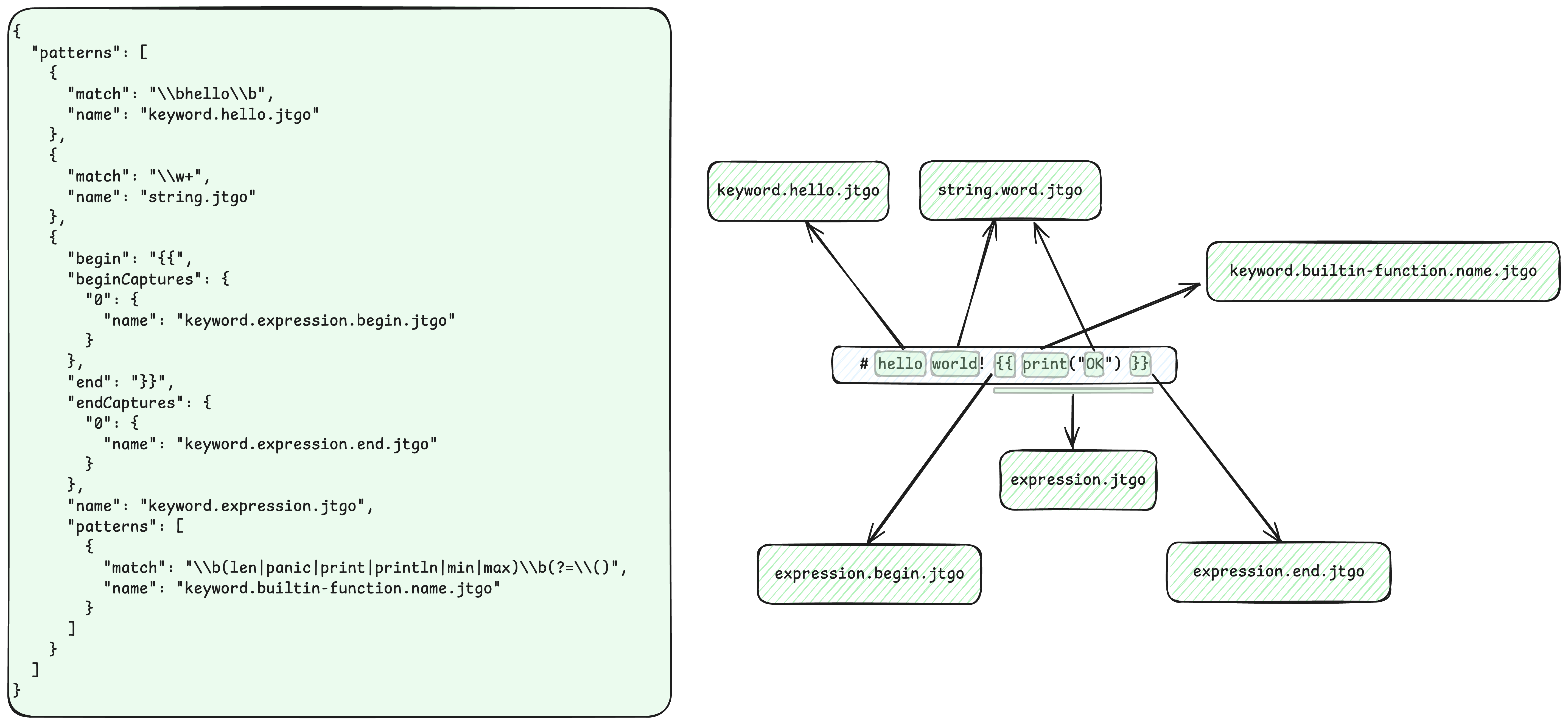
patterns 列表中的每一个 item 都是一个规则,在 Textmate 中被称为 Rule Key。
- 当 Textmate 引擎匹配到
hello时,会将其标记为keyword.hello作用域。 - 当 Textmate 引擎匹配到
\\w+,也就是任意单词字符时,会将其标记为string.word.jtgo作用域。 - 当 Textmate 引擎匹配到
{{时,接着会继续匹配直到匹配到}},并且将{{和}}之间的内容使用子规则(嵌套规则)进行匹配。这个规则的作用域映射如下: {{->expression.begin.jtgo}}->expression.end.jtgo{{ print("OK") }}->expression.jtgoprint->keyword.builtin-function.name.jtgo- 对于
{{和}}之间的内容,当 Textmate 引擎匹配到\\b(len|panic|print|println|min|max)\\b(?=\\()时,也就是(之前的len、panic、print、println、min或max时,会将其标记为keyword.builtin-function.name.jtgo作用域。
例如下面的文本,经过 Textmate 引擎的分词后,会被标记为如下的 Token:
4.1 JSON 的分词规则
直接进阶到 JSON 的分词规则,详细规则内容以 VSCode 的内置 JSON 分词规则为例:
-
整个文件内容默认会被最外层的
scopeName匹配,既所有的内容都会被标记上source.json作用域。整个 JSON 文件的作用域是
source.json -
引擎会将第一个字符从最外层的
patterns数组开始匹配,从上至下按顺序匹配每一个规则,直到匹配到一个规则为止。JSON 的最外层
patterns只有一个规则value规则,第一个字符会使用value的规则进行匹配。 -
对于每个规则,如果规则中未包含
match或begin和end,则会直接递归匹配patterns中的规则。反之分为两种情况: - 只有
match字段,会尝试匹配当前规则的match字段,如果匹配成功,则将匹配到的字符标记为name字段和captures字段中的作用域,并继续匹配下一个字符。若匹配失败,则会跳出规则,回到patterns中继续匹配下一个规则。 -
只有
begin和end字段,会尝试匹配begin规则,匹配成功时会继续将匹配到字符标记为beginCaptures字段中的作用域(end字段同理),如果规则中包含patterns字段,则下一个字符会使用patterns中的规则进行匹配,直到匹配到end规则为止。如果规则中未包含patterns字段,则会直接匹配end字段。匹配到end字段后,会将当前规则匹配到所有的字符都标记上name作用域,begin所匹配字符和end所匹配字符之间的内容会额外标记上contentName作用域。最后会跳出当前递归规则,回到上一层规则继续匹配。JSON 的
value规则内只有一个patterns字段,则会直接递归匹配patterns中的规则。JSON 文件的第一个字符是
{,引擎会尝试匹配constant规则,其中只有一个match规则,但匹配失败,所以会跳出constant规则,回到value的patterns规则中继续匹配下一个规则。以此类推,
number、string和array规则都会匹配失败。接着会匹配
object规则,{字符会匹配成功其begin字段规则,接着下一个字符会使用object规则中的patterns规则进行匹配。 -
若未匹配到
patterns中的任何规则,则会继续匹配下一个字符。
下面是 Textmate 解析 JSON 内容过程一步步拆解后的示意图:

5. 附录
正则表达式温习